Psycholinguistics is the study of the relationships between linguistic behaviour and psychological processes, including the process of language acquisition.
There have been multiple factors that are known to affect lexical processing, and we might want to consider those in building NLP models. Such factors include not only obvious things like word length and number of syllabus, but also word prevalence/frequency.
Word prevalence data in particular are useful for gauging the difficulty of words and could be used a metric for the richness of vocabulary.
Word prevalences across various media has been studied and there are databases to use in analyses, e.g., the data complied by Brysbaert and colleagues.
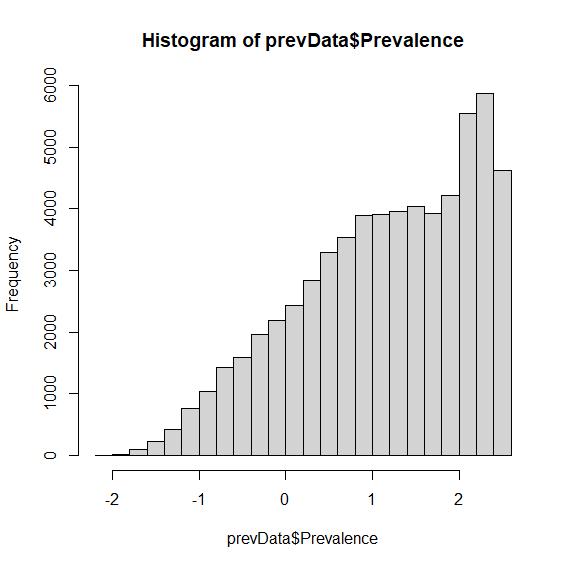
Here is the distribution of prevalences scores across the 61855 lemmas in the Brysbaert dataset. The higher the prevalence, the more commonplace the word.
For example, 'about' has a score of 2.576, while 'sortilege' has a score of -0.817.
Here is the distribution across the available lemmas.
How about we apply this to look at vocab usage in the New York Post? Can we look at differences in word-make up across articles of differing topics?
We can try to use the data available on kaggle provided by nzalake52.
A custom script was used to do the data scraping from the above kaggle text file.
I calculated the number of words per article, number of unique words per article (minus stopwords), and also the median and minimum word prevalances in each article.
I then calculated the average across each topic.
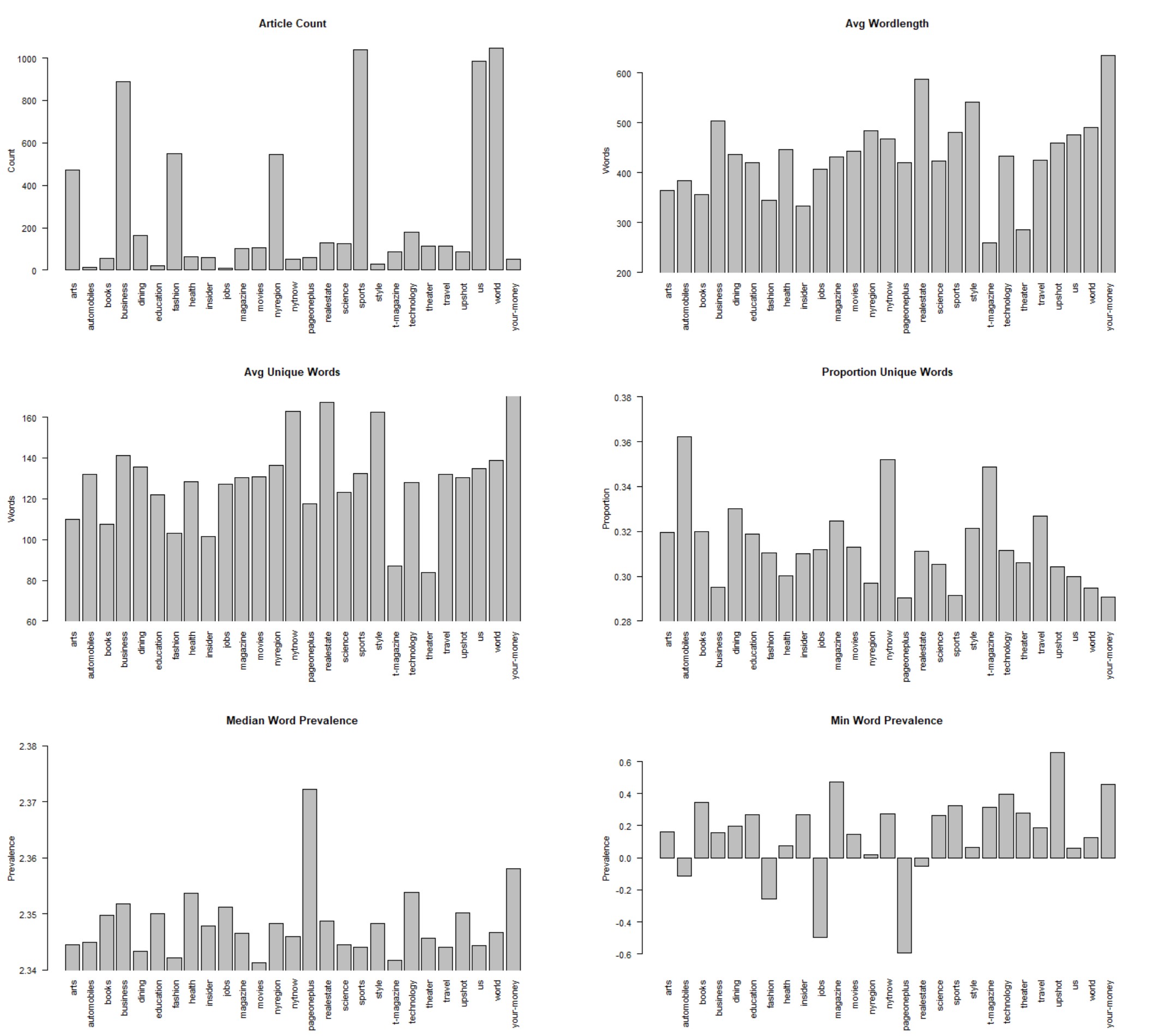
Looks like there is some variation in word length, and work prevalence depending on the topic.
Of course, some topics are more jargon-y then others, so it should not be so surprising that there would be variation.